PAM算法——数据挖掘 编写 2018-10-26 浏览: 1. 实现PAM算法对部分含有高斯噪声的waveform数据集进行聚类1.1. PAM算法简介 PAM方法于1987年提出,用于l1范数和其他距离的工作。 k-medoid是一种经典的聚类分割技术,它将n个对象的数据集聚为k个聚类,假设聚类的数量k是先验的。如果未知,则可以使用诸如轮廓的方法来确定k。 与k均值相比,它对噪声和异常值更具鲁棒性,因为它最小化了成对差异的总和,而不是欧几里德距离的平方和。 可以将medoid定义为群集的对象,其与群集中的所有对象的平均差异最小。即,它是群集中位于最中心的点(迭代选取最中心的点,而非Kmeans的中心计算值,抗噪声能力更强)。 展开阅读全文 »
Kmeans算法——数据挖掘 编写 2018-10-24 浏览: 1. 实现K-means算法对无噪声的waveform数据集进行分割1.1. K-means算法简介 k均值聚类是一种矢量量化方法,最初来自信号处理,是数据挖掘中聚类分析的常用方法。 k均值聚类的目的是将n个观测值划分为k个聚类,其中每个观测值属于具有最近均值的聚类,作为聚类的原型。这导致数据空间划分为Voronoi单元。 展开阅读全文 »
QuickSort 编写 2018-10-23 浏览: 1. 快速排序概念快速排序(Quick Sort)由C. A. R. Hoare在1962年提出。它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。快速排序是不稳定的算法,时间复杂度在最坏情况下是O(N^2),平均的时间复杂度是O(N*lgN)。 展开阅读全文 »
预处理——数据挖掘 编写 2018-10-21 浏览: 1. 在Linux系统安装Python及数据处理所需的numpy、pandas库之前尝试手动下载numpy库,解压,然后按提示安装,却发现numpy库依赖上级库nose,又下载nose库,但在手动安装pandas库时出错…后发现可通过pip的简单方式安装,自动解决依赖,相比于需要手动下载安装上级依赖的手动安装方式更方便,安装代码如下 展开阅读全文 »
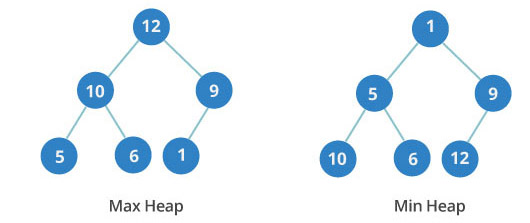
最小堆与最大堆 编写 2018-10-16 浏览: 堆是一种经过排序的完全二叉树,对其中任一非终端节点,其数据值不大于(或不小于)其左右子节点的值。 最小堆(最大堆)堆能保证堆顶元素最小(最大),相比于用数组存放数据,如果要查找所有数据中最小(最大)的数据时,数组的时间复杂度为O(n),而最小堆(最大堆)的时间复杂度为O(1)。 而数据增删数据时,需要保证最小堆(最大堆)的动态可维护性仅需O(logN)。因此在特定的需求环境,最小堆(最大堆)这种数据结构非常高效。 展开阅读全文 »